메모리 풀 : part 4 - 표준 스마트 포인터의 한계와 다른 시스템의 해결책
Memory Pool Part 4: 표준 스마트 포인터의 한계와 다른 시스템의 해결책
이전 글에서 우리는 메모리 풀이 원시 포인터에서는 효과적으로 작동하지만, 표준 스마트 포인터(std::shared_ptr, std::unique_ptr)와 결합할 때는 그 효과가 제한적이라는 것을 살펴보았습니다. 그러나 고성능 컴퓨팅, 게임 엔진, 금융 거래 시스템과 같은 성능이 중요한 환경에서는 메모리 관리 최적화가 필수적입니다. 이번 글에서는 표준 스마트 포인터의 한계를 더 자세히 살펴보고, 다양한 시스템에서 이러한 한계를 어떻게 극복하는지 알아보겠습니다.
1. 표준 스마트 포인터의 한계
1.1. 성능 오버헤드의 원인
표준 라이브러리의 스마트 포인터가 성능 면에서 제한적인 이유를 좀 더 깊이 살펴보겠습니다:
1.1.1. 컨트롤 블록: std::shared_ptr의 숨겨진 비용
std::shared_ptr가 메모리 풀과 효율적으로 작동하지 않는 핵심 원인은 ‘컨트롤 블록(control block)’이라는 추가 메모리 구조 때문입니다. 컨트롤 블록이란 무엇일까요?
// std::shared_ptr의 단순화된 내부 구조
template <typename T>
class shared_ptr {
private:
T* ptr; // 관리되는 객체를 가리키는 포인터
control_block* cntrl; // 참조 카운트 및 메타데이터를 포함하는 컨트롤 블록
};
컨트롤 블록은 다음과 같은 요소를 포함합니다:
- 공유 참조 카운트(shared reference count): 강한 참조의 수를 추적
- 약한 참조 카운트(weak reference count):
std::weak_ptr의 수를 추적 - 삭제자(deleter): 객체를 해제하는 방법 지정
- 할당자(allocator): 메모리 할당 방법 지정
Microsoft Visual C++ (MSVC) 의 std::shared_ptr 구현
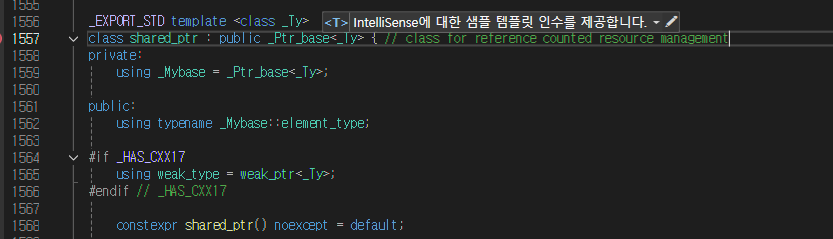
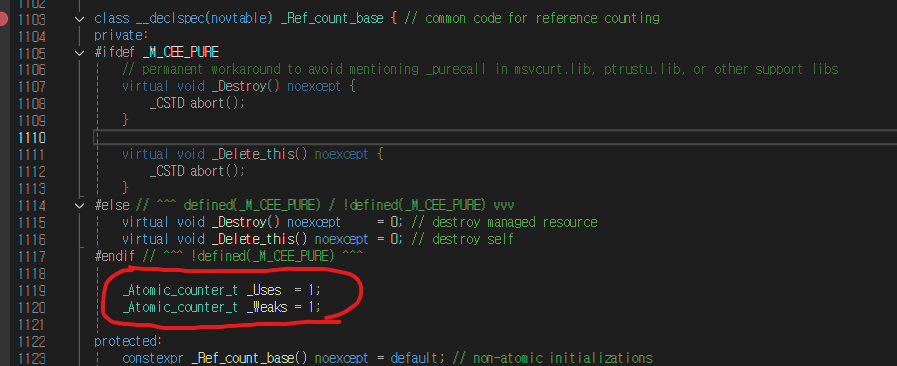
컨트롤 블록의 일반적인 내부 구조는 다음과 같습니다:
// 컨트롤 블록의 단순화된 구조
struct control_block {
std::atomic<long> shared_count; // 공유 참조 카운트
std::atomic<long> weak_count; // 약한 참조 카운트 + 1
virtual void destroy() = 0; // 관리되는 객체 소멸
virtual void deallocate() = 0; // 관리되는 객체와 컨트롤 블록 할당 해제
virtual ~control_block() = default;
};
// T 타입에 특화된 구현
template <typename T, typename Deleter, typename Allocator>
struct control_block_impl : control_block {
T* ptr; // 관리되는 객체
Deleter del; // 커스텀 삭제자
Allocator alloc; // 커스텀 할당자
void destroy() override {
del(ptr); // 삭제자를 사용해 객체 소멸
}
void deallocate() override {
// 할당자를 사용해 메모리 해제
typedef typename std::allocator_traits<Allocator>::
template rebind_alloc<control_block_impl> AllocType;
AllocType rebound(alloc);
this->~control_block_impl();
rebound.deallocate(this, 1);
}
};
이 컨트롤 블록은 std::shared_ptr가 생성될 때마다 동적으로 할당되며, 여기에 몇 가지 문제가 있습니다:
- 추가 메모리 할당: 객체와 컨트롤 블록의 두 가지 별도 할당이 필요합니다.
- 메모리 단편화: 객체와 컨트롤 블록이 메모리의 다른 영역에 위치하여 캐시 효율성이 저하됩니다.
- 간접 참조: 컨트롤 블록에 접근하기 위한 추가적인 포인터 역참조가 필요합니다.
- 가상 함수 호출: 다형성을 위한 가상 함수 호출이 발생하므로 인라인화가 어렵습니다.
std::make_shared는 객체와 컨트롤 블록을 하나의 메모리 블록에 함께 할당하여 일부 문제를 해결하지만, 커스텀 메모리 풀과 함께 사용하기는 여전히 어렵습니다.
1.1.2. 스레드 안전성과 원자적 연산
std::shared_ptr의 참조 카운트 변경은 스레드 안전을 위해 원자적 연산을 사용합니다:
// 참조 카운트 증가 (내부 구현 간소화)
void increment_ref_count() {
std::atomic_fetch_add_explicit(&count, 1, std::memory_order_relaxed);
}
// 참조 카운트 감소 (내부 구현 간소화)
void decrement_ref_count() {
if (std::atomic_fetch_sub_explicit(&count, 1, std::memory_order_acq_rel) == 1) {
delete_managed_object();
}
}
이러한 원자적 연산은 일반 정수 연산보다 상당히 비용이 높으며, 특히 멀티코어 시스템에서 캐시 일관성 프로토콜을 통한 추가 오버헤드를 발생시킵니다.
1.1.3. 타입 소거와 가상 함수 오버헤드
std::shared_ptr의 커스텀 삭제자와 할당자 지원은 내부적으로 타입 소거와 가상 함수 호출을 사용합니다. 이로 인해:
- 런타임 다형성에 대한 오버헤드 발생
- 컴파일러의 최적화 기회 감소
- 간접 호출로 인한 추가 지연 시간
1.2. 메모리 사용량 증가
표준 스마트 포인터는 추가 메타데이터 저장으로 인해 메모리 사용량이 증가합니다:
원시 포인터(T*): 4-8바이트
std::unique_ptr: 8-16바이트 (삭제자에 따라 다름)
std::shared_ptr: 16바이트 + 컨트롤 블록(24-64바이트)
컨트롤 블록의 크기는 다음과 같은 요소에 따라 달라집니다:
- 원자적 참조 카운터 (일반적으로 8바이트 x 2)
- 가상 함수 테이블 포인터 (8바이트)
- 커스텀 삭제자 (크기는 다양함, 최소 8바이트)
- 할당자 상태 (크기는 다양함)
수백만 개의 객체를 관리하는 시스템에서는 이러한 오버헤드가 상당한 메모리 부담을 초래할 수 있습니다.
2. 게임 엔진의 스마트 포인터 구현
게임 엔진은 고성능과 예측 가능한 메모리 사용이 필수적인 분야입니다. Unreal Engine과 같은 상용 게임 엔진은 어떻게 이 문제를 해결했는지 살펴봅시다.
2.1. Unreal Engine의 접근법
Unreal Engine은 자체 스마트 포인터 구현을 통해 성능과 안전성의 균형을 맞추고 있습니다:
2.1.1. 침투적 참조 카운팅
// Unreal Engine의 참조 카운팅 기반 클래스 (간소화)
class FReferenceCounted {
protected:
mutable int32 ReferenceCount;
public:
FReferenceCounted() : ReferenceCount(0) {}
void AddRef() const {
++ReferenceCount;
}
void Release() const {
if (--ReferenceCount == 0) {
delete this;
}
}
};
이 접근법의 장점:
- 컨트롤 블록이 필요 없어 메모리 할당 감소
- 객체 내에 참조 카운트가 있어 메모리 지역성 향상
- 원자적 연산이 필요한 경우에만 사용 (스레드 안전이 필요한 객체용)
- 컨트롤 블록 생성/할당/해제로 인한 오버헤드 제거
2.1.2. 특화된 포인터 유형
Unreal Engine은 다양한 사용 사례에 맞는 여러 스마트 포인터 유형을 제공합니다:
// 공유 소유권 포인터
TSharedPtr<FMyClass> Ptr = MakeShared<FMyClass>();
// Null이 될 수 없는 참조 형태
TSharedRef<FMyClass> Ref = MakeShared<FMyClass>();
// 약한 참조
TWeakPtr<FMyClass> WeakPtr = Ptr;
// 고유 소유권 포인터
TUniquePtr<FMyClass> UniquePtr = MakeUnique<FMyClass>();
- 사용 패턴에 최적화된 구현
- 엔진의 메모리 할당자와 통합
- 추가적인 게임 개발 기능 (디버깅, 직렬화 등)
2.1.3. 통합된 컨트롤 블록
Unreal Engine의 TSharedPtr는 표준 라이브러리의 std::shared_ptr와 다르게 컨트롤 블록을 관리합니다:
// Unreal Engine의 컨트롤 블록 구현 (간소화)
struct FSharedReferencer {
struct FReferenceControllerBase {
uint32 SharedReferenceCount;
uint32 WeakReferenceCount;
FReferenceControllerBase() : SharedReferenceCount(1), WeakReferenceCount(1) {}
virtual ~FReferenceControllerBase() {}
virtual void DestroyObject() = 0;
};
template <typename ObjectType>
struct TReferenceController : public FReferenceControllerBase {
ObjectType* Object;
TReferenceController(ObjectType* InObject) : Object(InObject) {}
virtual void DestroyObject() override {
delete Object;
}
};
FReferenceControllerBase* ReferenceController;
};
주요 최적화 포인트:
- 원자적 연산은 멀티스레드 컨텍스트에서만 사용
- 엔진의 메모리 할당 시스템과 통합하여 컨트롤 블록 할당 최적화
- 자주 사용되는 객체 유형에 특화된 컨트롤 블록 구현 제공
3. 고성능 서버와 데이터베이스의 접근법
고성능 서버와 데이터베이스는 극도로 최적화된 메모리 관리가 필요한 또 다른 분야입니다.
3.1. Redis의 메모리 관리
Redis는 인메모리 데이터 스토어로, 메모리 관리가 핵심입니다. Redis는 다음과 같은 메모리 최적화 기법을 사용합니다:
3.1.1. 객체 풀과 공유 객체
Redis는 작은 정수와 같이 자주 사용되는 값을 위한 공유 객체 풀을 구현합니다. 이 접근법은 동일한 작은 정수 값들이 여러 번 생성되는 것을 방지하여 메모리 사용량을 크게 줄입니다.
3.1.2. 침투적 참조 카운팅
Redis는 객체 구조체 내에 직접 참조 카운트를 포함시키는 침투적 참조 카운팅을 사용합니다. 이 방식은 별도의 컨트롤 블록 할당이 필요없어 메모리 효율성과 캐시 지역성을 향상시킵니다.
3.2. 메모리 관리 최적화 기법
고성능 서버와 데이터베이스에서 자주 사용되는 기타 최적화 기법들입니다:
-
슬랩 할당자(Slab Allocator): 동일한 크기의 객체를 효율적으로 할당하고 해제하기 위한 메모리 관리 기법입니다. Memcached와 많은 커널 레벨 시스템에서 사용됩니다.
-
영역 기반 할당(Arena Allocation): 관련 객체들을 함께 할당하고 한 번에 해제할 수 있는 메모리 관리 기법입니다. 이 방식은 개별 해제 오버헤드를 줄이고 메모리 단편화를 감소시킵니다.
-
특수 메모리 관리자: 많은 고성능 시스템은 애플리케이션 특화된 메모리 관리자를 사용하여 일반 힙 할당의 오버헤드를 피합니다.
4. 금융 시스템의 메모리 관리
금융 거래 시스템은 초저지연이 필수적이며, 메모리 관리에 대한 특별한 접근법을 사용합니다.
4.1. 사전 할당 및 풀링
많은 금융 시스템은 시작 시 필요한 모든 메모리를 사전 할당하고 풀링합니다. 이러한 방식은 주문, 거래, 시장 데이터와 같은 핵심 데이터 구조를 위해 미리 메모리를 할당하고, 런타임 중에는 이 풀에서 객체를 재사용합니다.
- 거래 처리 중 동적 메모리 할당 방지
- 예측 가능한 메모리 사용 패턴
- 메모리 단편화 감소
4.2. 제로 할당 접근법
일부 극도로 지연에 민감한 금융 시스템은 “제로 할당(zero allocation)” 접근법을 사용합니다. 이 방식에서는 시스템 시작 시 모든 객체가 사전 할당되며, 핫 경로(성능이 중요한 부분)에서는 새로운 메모리 할당이 전혀 발생하지 않습니다.
- 거래 처리 중 동적 할당 없음
- 예측 가능한 지연 시간
- 가비지 컬렉션 일시 중지(GC pause) 없음
4.3. 커스텀 메모리 레이아웃
일부 고성능 금융 시스템은 캐시 효율성을 극대화하기 위해 데이터 구조의 메모리 레이아웃을 세밀하게 제어합니다. 이는 데이터 정렬, 패딩 최소화, 캐시 라인 최적화 등을 포함하며, 스마트 포인터 대신 인덱스나 핸들 기반 시스템을 사용하는 경우가 많습니다.
5. 임베디드 시스템과 실시간 시스템
임베디드 및 실시간 시스템은 제한된 리소스와 예측 가능한 성능이 필요합니다.
5.1. 정적 메모리 할당
많은 임베디드 시스템은 동적 할당을 완전히 방지하고 정적 메모리만 사용합니다. 모든 객체는 컴파일 시간에 결정된 크기로 정적으로 할당되며, 런타임 중에는 추가 메모리 할당이 발생하지 않습니다.
- 메모리 사용의 예측 가능성
- 메모리 단편화 없음
- 실시간 성능 보장
5.2. 실시간 메모리 관리
실시간 시스템에서는 메모리 할당/해제 작업이 예측 가능한 시간 내에 완료되어야 합니다. 이를 위해 다음과 같은 기법이 사용됩니다:
-
고정 크기 블록 할당자: 동일한 크기의 메모리 블록을 관리하여 할당/해제 시간을 일정하게 유지합니다.
-
이중 버퍼링: 두 개의 메모리 영역을 번갈아가며 사용하여 한 영역이 처리되는 동안 다른 영역에서 새 데이터를 구성할 수 있게 합니다.
-
메모리 풀 계층: 다양한 크기의 메모리 요청을 처리하기 위해 여러 크기의 메모리 풀을 계층적으로 구성합니다.
5.3. 임베디드 스마트 포인터
일부 임베디드 시스템은 제한된 형태의 스마트 포인터를 사용합니다:
-
정적 할당된 객체용 참조 카운팅: 동적 할당 없이 참조 카운팅 메커니즘만 사용하는 단순화된 스마트 포인터입니다.
-
풀 기반 스마트 포인터: 미리 할당된 메모리 풀에서만 객체를 관리하는 제한된 스마트 포인터입니다.
-
범위 기반 메모리 관리: 특정 범위 내에서만 유효한 객체를 관리하는 단순화된 스마트 포인터 방식입니다.
이러한 접근법들은 일반적인 C++ 스마트 포인터의 유연성을 일부 희생하지만, 실시간 제약 조건을 만족시키고 제한된 리소스를 효율적으로 사용할 수 있습니다.
다음 포스트에서는 컨트롤 블록 최적화와 자체 스마트 포인터 구현에 대해 더 자세히 알아보고, 이를 통해 메모리 풀과 스마트 포인터를 효과적으로 결합하는 방법을 살펴보겠습니다.
댓글