클린코드 13장: 동시성
그동안 컴퓨터 책을 참 많이도 샀습니다. 마침 회사에서 클린코드 13장을 정리해야했고, 앞으로 클린코드 뿐만 아니라 많이도 산 책들을 조금씩 정리해보려고 합니다.
클린코드 13장: 동시성 종합 정리
개요
- 동시성과 깔끔한 코드는 양립하기 어렵다
- 이 장에서는:
- 여러 스레드를 동시에 돌리는 이유
- 여러 스레드를 동시에 돌리는 어려움
- 동시성을 테스트하는 방법과 문제점
동시성이 필요한 이유
- 동시성은 결합을 없애는 전략으로, 무엇(what)과 언제(when)를 분리
- 스레드가 하나인 프로그램은 무엇과 언제가 서로 밀접하게 결합
- 무엇과 언제를 분리하면 애플리케이션 구조와 효율이 극적으로 개선
- 동시성은 구조적 개선만이 아닌 응답시간과 작업 처리량 개선이 필요할 때도 사용
동시성에 관한 미신과 오해
- 미신: “동시성은 항상 성능을 높인다”
- 실제로는 다소 부하를 유발할 수 있음
- 미신: “동시성을 구현해도 설계는 변하지 않는다”
- 실제로는 동시성을 구현하려면 근본적인 설계 전략을 재고해야 함
- 동시성은 복잡성이 증가하고, 버그는 재현이 어려움
동시성 오류가 발생하는 이유
동시성 오류는 주로 공유 자원에 대한 경쟁 상태(race condition)에서 발생합니다. 간단한 증가 연산도 어셈블리 수준에서는 여러 단계로 이루어집니다:
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
int counter = 0;
void incrementCounter(int iterations) {
for (int i = 0; i < iterations; i++) {
// counter++ 연산은 실제로 다음과 같은 단계로 이루어짐:
// 1. 메모리에서 counter 값을 레지스터로 로드
// 2. 레지스터에서 값을 1 증가
// 3. 증가된 값을 메모리에 다시 저장
counter++;
}
}
int main() {
const int NUM_THREADS = 4;
const int ITERATIONS = 100000;
// 여러 스레드가 동시에 counter 증가
std::vector<std::thread> threads;
for (int i = 0; i < NUM_THREADS; i++) {
threads.push_back(std::thread(incrementCounter, ITERATIONS));
}
// 모든 스레드 종료 대기
for (auto& t : threads) {
t.join();
}
// 예상: NUM_THREADS * ITERATIONS = 400000
// 실제: 경쟁 상태로 인해 이보다 작은 값이 출력됨
std::cout << "Counter 값: " << counter << std::endl;
std::cout << "예상 값: " << NUM_THREADS * ITERATIONS << std::endl;
return 0;
}
동시성 방어 원칙
단일 책임 원칙(SRP)
- 주어진 메서드/클래스/컴포넌트를 변경할 이유가 하나여야 한다는 원칙
- 동시성 관련 코드는 다른 코드와 분리해야 함
// 잘못된 예: 과일 구매 로직과 동시성 코드가 혼합
class FruitBuyer {
public:
void buyFruit(Fruit& friut) {
std::lock_guard<std::mutex> lock(mutex);
checkFruit(friut);
payFruit(friut);
getFruit(friut);
}
private:
std::mutex mutex;
void checkFruit(Fruit& friut) { /* ... */ }
void payFruit(Fruit& friut) { /* ... */ }
void getFruit(Fruit& friut) { /* ... */ }
};
// 과일 사기 비즈니스 로직
class FruitBuyer {
public:
void buyFruit(const std::string& fruit) {
checkFruit(fruit);
payFruit(fruit);
getFruit(fruit);
}
private:
void checkFruit(const std::string& fruit);
void payFruit(const std::string& fruit);
void getFruit(const std::string& fruit);
};
// 동시성 처리 담당 클래스
class ConcurrentFruitBuyer {
public:
ConcurrentFruitBuyer(FruitBuyer& buyer) : buyer(buyer) {}
void buyFruitSafely(const std::string& fruit) {
std::lock_guard<std::mutex> lock(mutex);
buyer.buyFruit(fruit);
}
private:
FruitBuyer& buyer;
std::mutex mutex;
};
- 과일 구매는 FruitBuyer
- 동시성 처리는 ConcurrentFruitBuyer
자료 범위 제한
- 공유 데이터를 줄이는 것이 가장 좋고, 꼭 공유해야 한다면 임계영역으로 보호하세요.
자료 사본을 사용
- 공유 데이터를 직접 수정하기보다, 복사본을 만들어 작업한 후 필요할 때만 반영하는 것이 안전합니다
스레드는 가능한 독립적으로 구현
- 지역 변수를 사용하세요.
- 다른 스레드와 자원을 공유하지 않는 스레드 사용 (TLS: Thread Local Storage)
실행 모델 이해하기
주요 용어
- 한정된 자원: 크기나 숫자가 제한된 자원 (데이터베이스 연결, 읽기/쓰기 버퍼 등)
- 상호 배제: 한 번에 한 스레드만 공유 자원에 접근 가능하도록 하는 기법
- 기아: 스레드가 필요한 자원을 계속 얻지 못하는 상태
- 데드락: 여러 스레드가 서로가 가진 자원을 기다리며 진행하지 못하는 상태
- 라이브락: 스레드가 계속 동작하지만 진전은 없는 상태
모델1: 생산자-소비자
- 생산자 스레드는 작업을 생성해 대기열에 추가, 소비자 스레드는 대기열에서 작업을 가져와 처리합니다.
- 대기열이 가득 찻는데 소비자에게 알림을 전달 못하거나, 대기열이 비었는데 생산자에게 알림을 전달 못함 -> 데드락 발생
모델2: 읽기-쓰기
- 읽기-쓰기 모델은 읽기는 동시에 가능하고 쓰기는 혼자 해야 하는 구조입니다
- 처리율을 높이려고 읽기를 계속 허용하다 보면, 쓰기가 계속 기다리게 되어 기아가 발생할 수 있습니다.
모델3: 식사하는 철학자들
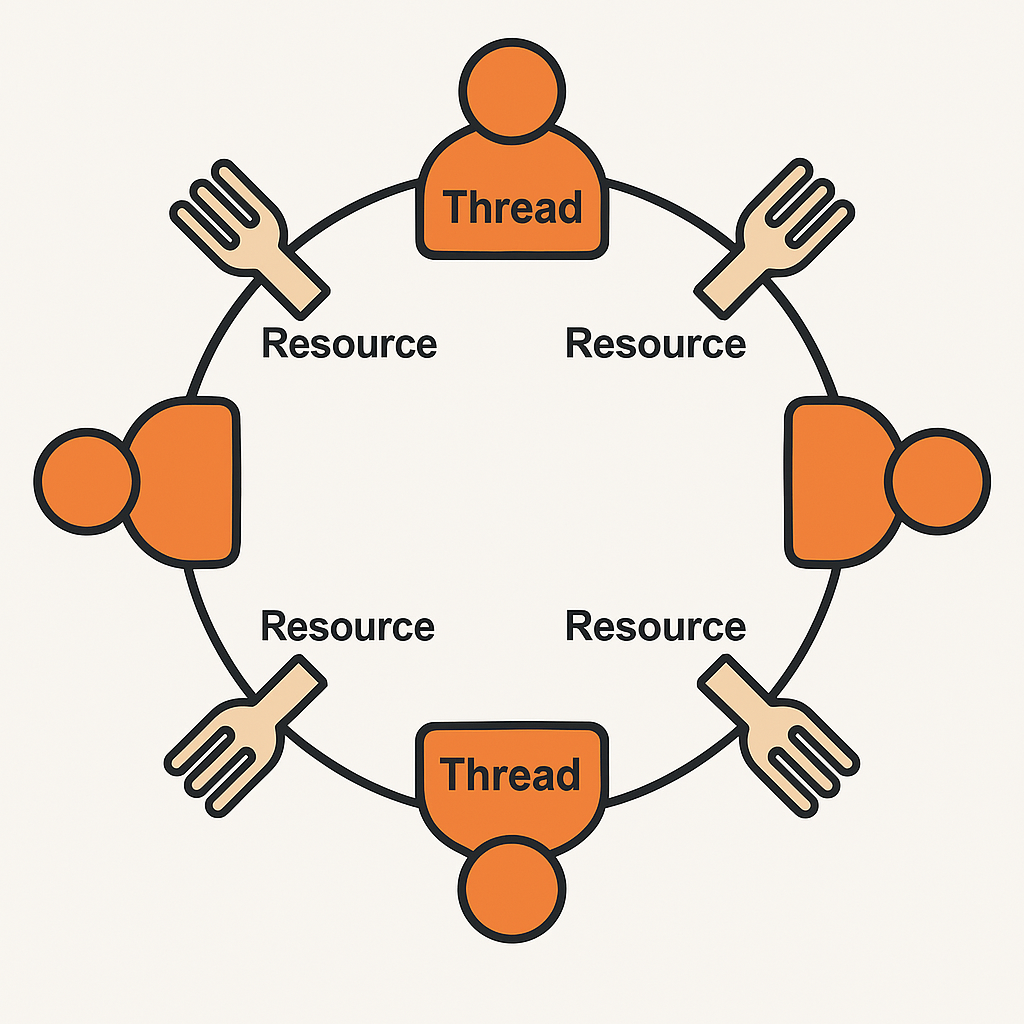
- 여러 스레드가 제한된 자원을 사용해야 할 때 발생하는 대표적인 동기화 문제입니다. (철학자 = 스레드 / 포크 = 자원)
- 각 철학자가 양쪽 포크를 집어야 식사를 할 수 있는데, 모두가 동시에 한쪽 포크만 들고 다른 포크를 기다리면 → 데드락 발생
- 또는 누군가 계속 식사하고 다른 철학자가 기회를 못 받으면 → 기아(Starvation) 발생
동기화하는 메서드 사이의 의존성 관리
원칙: 동기화하는 메서드 사이에 존재하는 의존성을 이해하라
- 공유 객체는 동기화 문제가 없도록 메서드를 하나만 제공하는 것이 가장 안전합니다.
- 하지만 여러 메서드가 필요한 상황이라면, 동기화 방식에 대한 설계가 중요합니다.
해결 방법
| 방법 | 설명 |
|---|---|
| 클라이언트에서 잠금 | 사용하는 쪽(호출부)에서 락을 걸고 여러 메서드를 호출 |
| 서버에서 잠금 | 공유 객체 내부에서 각 메서드마다 락을 걸어 동기화 |
| 연결 서버(또는 관리자 서버) | 공유 객체 접근을 전담하는 별도의 스레드나 서버를 두고 요청만 전달 |
동기화 부분을 작게 만들기
- 락을 거는 코드(임계영역)가 클수록 처리 속도가 느려지고, 다른 스레드가 오래 기다리게 됩니다.
- 꼭 필요한 코드에만 락을 걸어 동기화 범위를 최소화하는 것이 좋습니다.
예시 상황
은행 계좌(balance)를 여러 스레드가 접근하는 상황입니다.
안 좋은 예시 (동기화 범위가 너무 넓음)
- 동기화 범위가 크면 불필요하게 오래 기다림
void deposit(int amount) {
std::lock_guard<std::mutex> lock(mtx);
balance += amount;
/*
여러 작업 처리
*/
}
개선된 예시 (동기화 범위 최소화)
- 공유 자원(balance)만 잠금
- 출력은 락 없이 처리 가능
void deposit(int amount) {
// 공유 자원 접근만 잠금
std::lock_guard<std::mutex> lock(mtx);
balance += amount;
}
/*
여러 작업 처리
*/
올바른 종료 코드 구현의 어려움
- 부모 스레드가 여러 자식 스레드를 만들고, 자식 스레드가 모두 종료된 후 부모가 자원을 해제하는 상황을 가정 합니다.
- 하지만 자식 스레드가 데드락에 걸렸거나, 자식 스레드끼리 생산자-소비자 관계로 묶여 있다면?
문제 상황1 — 자식 스레드가 데드락에 걸린 경우
- 부모는 자식 스레드 종료를 기다리는데, 자식 스레드가 데드락에 걸려 영원히 종료되지 않음
문제 상황2 — 생산자-소비자 관계인 자식 스레드
- 부모가 자식 스레드 모두 종료하라고 알렸는데
- 소비자는 버퍼가 비어서 생산자를 기다리고 있고
- 생산자는 이미 종료했거나 멈춰있는 상황 → 서로 대기 → 데드락 또는 무한 대기
스레드 코드 테스트하기
동시성 코드는 테스트하기 어렵습니다:
- 문제를 노출하는 테스트 케이스 작성 → 예: 스레드 함수 안에 sleep 같은 지연을 넣어서 타이밍 충돌 유도
- 프로그램 설정, 시스템 설정, 부하를 다양하게 변경하며 테스트
- 다양한 환경에서 반복 테스트 필요
동시성 코드 구현 지침
-
일회성 오류도 넘기지 마라: 간헐적으로 발생하는 동시성 문제는 무시하지 말고 반드시 해결해야 합니다.
-
다중 스레드를 고려하지 않은 순차 코드부터 제대로 구현: 먼저 단일 스레드 코드가 올바르게 동작하는지 확인한 후, 동시성 지원을 추가합니다.
-
다중 스레드를 쓰는 코드 부분을 다양한 환경에 쉽게 넣을 수 있도록 구현: 동시성 코드를 모듈화하고 환경에 따라 설정 가능하게 만듭니다.
-
다중 스레드를 쓰는 코드 부분을 상황에 맞춰 조정할 수 있게 작성: 스레드 수, 대기열 크기 등을 조정 가능하게 설계합니다.
-
프로세서 수보다 많은 스레드를 돌려 테스트: 스레드 간 컨텍스트 전환을 강제하여 잠재적 문제를 발견합니다.
-
다른 플랫폼에서 돌려 테스트: 서로 다른 운영 체제, 하드웨어에서 테스트하여 플랫폼 의존적 문제를 발견합니다.
-
코드에 보조 코드를 넣어 강제로 실패를 유발하는 테스트: 스레드 스케줄링을 인위적으로 변경하여 경쟁 상태를 발생시키는 테스트를 수행합니다.
클린코드를 넘어서: 최신 동시성 문제 해결 기법
클린코드 13장에서 다루지 않은 여러 고급 동시성 기법들을 소개합니다. 이러한 기술들은 복잡한 멀티스레드 환경에서 발생하는 문제를 효과적으로 해결하는 데 도움이 됩니다.
CAS(Compare-And-Swap) 연산
CAS는 락 프리 프로그래밍의 기본이 되는 원자적 연산입니다. 메모리의 값을 예상 값과 비교한 후, 일치할 경우에만 새 값으로 교체합니다.
#include <atomic>
template <typename T>
bool compare_and_swap(std::atomic<T>& value, T expected, T new_value) {
// 현재 값이 expected와 같으면 new_value로 교체하고 true 반환
// 그렇지 않으면 false 반환
return value.compare_exchange_strong(expected, new_value);
}
// 사용 예시: CAS 기반 스택
template <typename T>
class LockFreeStack {
private:
struct Node {
T data;
Node* next;
};
std::atomic<Node*> head{nullptr};
public:
void push(T value) {
Node* new_node = new Node{value, nullptr};
Node* old_head;
do {
old_head = head.load();
new_node->next = old_head;
} while (!head.compare_exchange_weak(old_head, new_node));
// CAS 실패 시 old_head가 자동으로 업데이트되어 다시 시도
}
bool pop(T& result) {
Node* old_head;
do {
old_head = head.load();
if (!old_head) return false; // 스택이 비어있음
} while (!head.compare_exchange_weak(old_head, old_head->next));
result = old_head->data;
delete old_head;
return true;
}
};
CAS 연산의 장점:
- 락 없이도 원자적 업데이트 가능
- 데드락 방지
- 높은 병렬성 제공
단점:
- ABA 문제 발생 가능 (값이 A→B→A로 변경되었을 때 변경을 감지하지 못함)
- 반복 시도로 인한 CPU 사용량 증가 가능
락 프리(Lock-Free) 프로그래밍
락 프리 프로그래밍은 뮤텍스와 같은 명시적인 잠금 메커니즘을 사용하지 않고도 스레드 안전성을 보장하는 기법입니다. 주로 원자적 연산(atomic operations)을 활용합니다.
#include <atomic>
class LockFreeCounter {
private:
std::atomic<int> count{0};
public:
void increment() {
count.fetch_add(1, std::memory_order_relaxed);
}
int get() const {
return count.load(std::memory_order_relaxed);
}
};
락 프리 알고리즘의 장점:
- 데드락 위험 없음
- 스레드 간 경쟁 감소로 성능 향상
- 우선순위 역전 문제 방지
메모리 순서(Memory Ordering)
C++11부터 도입된 메모리 순서 지정은 원자적 연산의 가시성(visibility)과 순서(ordering)를 세밀하게 제어할 수 있게 해줍니다.
std::atomic<bool> ready{false};
std::atomic<int> data{0};
// 스레드 1
void producer() {
data.store(42, std::memory_order_release);
ready.store(true, std::memory_order_release);
}
// 스레드 2
void consumer() {
while (!ready.load(std::memory_order_acquire)) {
// 스핀
}
// data가 반드시 42임을 보장
assert(data.load(std::memory_order_acquire) == 42);
}
RCU(Read-Copy-Update)
RCU는 주로 읽기 작업이 많은 데이터 구조에 적합한 동기화 기법입니다. 읽기 작업은 락 없이 진행하고, 쓰기 작업은 데이터의 새 복사본을 만들어 원자적으로 교체합니다.
template <typename T>
class RCUPointer {
private:
std::atomic<T*> ptr;
std::mutex write_mutex;
public:
RCUPointer(T* initial = nullptr) : ptr(initial) {}
// 읽기 - 락 없음
T* read() const {
return ptr.load(std::memory_order_acquire);
}
// 쓰기 - 새 객체 생성 후 포인터 교체
void update(T* new_data) {
std::lock_guard<std::mutex> lock(write_mutex);
T* old_data = ptr.load(std::memory_order_relaxed);
ptr.store(new_data, std::memory_order_release);
// 실제 RCU에서는 여기서 grace period를 기다림
// 그 후 old_data 삭제
}
};
하자드 포인터(Hazard Pointers)
메모리 관리 문제를 해결하는 기법으로, 스레드가 특정 메모리 영역을 사용 중임을 표시하여 다른 스레드가 해당 메모리를 해제하지 못하게 합니다.
// 간략화된 하자드 포인터 개념
thread_local Node* hazard_pointer = nullptr;
Node* read_node(std::atomic<Node*>& node_ptr) {
Node* ptr;
do {
ptr = node_ptr.load();
hazard_pointer = ptr; // 이 노드 사용 중임을 표시
} while (ptr != node_ptr.load()); // ABA 문제 방지
return ptr;
}
void retire_node(Node* node) {
// 모든 스레드의 hazard_pointer 검사
if (어떤_스레드라도_이_노드를_가리키는지_확인(node)) {
// 나중에 다시 시도
퇴출_큐에_추가(node);
} else {
// 안전하게 삭제 가능
delete node;
}
}
MVCC(다중 버전 동시성 제어)
데이터베이스 시스템에서 자주 사용되는 이 기법은 데이터의 여러 버전을 유지하여 읽기 작업이 쓰기 작업을 차단하지 않도록 합니다.
template <typename T>
class MVCCObject {
private:
struct Version {
T data;
long long timestamp;
Version* prev;
};
std::atomic<Version*> latest_version;
std::mutex write_mutex;
std::atomic<long long> global_timestamp{0};
public:
// 쓰기 - 새 버전 생성
void write(const T& new_data) {
std::lock_guard<std::mutex> lock(write_mutex);
Version* old_version = latest_version.load();
Version* new_version = new Version{
new_data,
global_timestamp.fetch_add(1),
old_version
};
latest_version.store(new_version);
}
// 읽기 - 타임스탬프에 따른 버전 선택
T read(long long read_timestamp = -1) const {
if (read_timestamp == -1) {
read_timestamp = global_timestamp.load();
}
Version* current = latest_version.load();
while (current && current->timestamp > read_timestamp) {
current = current->prev;
}
return current ? current->data : T{};
}
};
이러한 고급 동시성 기법들은 성능, 확장성, 안정성 측면에서 전통적인 락 기반 동기화보다 많은 이점을 제공할 수 있습니다. 다만 구현과 이해가 더 복잡하므로 신중하게 적용해야 합니다.
댓글